As an agile software consultant, I’ve now been involved with quite a few clients who are either trying out, or transitioning to, agile methods to deliver software within their organization. Some of the following types of questions are frequently raised:
Do we have to be completely agile for it to work at all?
How do we start being agile?
How do we work with parts of the organization that aren’t agile?
The organization already has a strict programme management methodology – how does agile work in that environment?
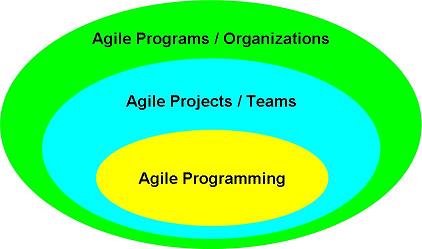
In trying to answer these questions, I think it can be helpful to think of agile software development to be made of 3 shells:
What this diagram shows is that we can think of breaking up all the different agile practices into 3 groups:
Agile Programming includes the development practices typically found in eXtreme Programming: evolutionary design, continuous integration, test-driven development, pair programming, domain-driven design.
Agile Projects / teams includes the agile project management and whole-team practices: short iterations, planning games, daily status meetings, information radioators, retrospectives, on-site customer proxy, acceptance-test driven requirements.
Agile Programs / organizations is referring to what happens when an agile project acts in an agile way with the bigger environment: frequent delivery to production hardware, on-site customer, frequent stake-holder meetings, agile support (e.g. from the IT operations dept.)
What I think is important is that there is strong requirement relationship looking inward, but a weaker requirement relationship looking outward. For example, if a whole program of work is going to be agile, its internal teams can’t be acting like mini waterfall projects. Similarly, the programmers on a 4 person team might well be able to practice agile programming techniques even if they don’t have an iterative development cycle.
I think breaking up agile in this way helps to answer the type of question we started out with. Some organizations might want to start with some of the more inward practices before pushing them further out. A classic example of this might be not being able to get a real on-site customer (an agile organization thing to do) but making do just with a customer proxy (which is what you’d have if you were trying to have an agile team.) Similarly, people might be willing for the team to deliver internally every iteration (maybe to UAT) but just aren’t setup to deliver to production more than once every 2 or 3 months.
Breaking up the practices in this way also helps you focus what you want to do first – it’s important to realise you might not need to be ‘completely agile‘ in one shell to support the next one out. As a first start to using agile, you might try having stake-holder meetings as part of an agile organization every iteration; have 2-week sprints, planning games, and daily status meetings as an agile team; and kick-off some technical practices like continuous integration to start out with. After a couple of iterations you’d probably find you’d need to add some more technical practices to support your iterations, and that you might need a designated customer proxy to better support the stake-holder community.
The final point to consider is how an agile project can work in the context of non-agile environmental constraints – this issue comes up frequently when introducing agile into businesses with large, dedicated IT organizations and management structures. By defining what we mean by an agile team or project, we are better able to define a strong interface between the agile team and the rest of the IT organisation. The team might need to produce relevant documentation, they might need to provide upfront requirements to other non-agile development teams. But the point is if they can’t work as part of an agile organization they can still look introspectively and find how they want to work as a team, and what technical practices they want to follow.
In closing, expecting an organization to become agile overnight is obviously unrealistic. A little analysis of breaking up the agile practices into broad areas can help transition an organization in a more controlled way.